
Opportunity Knocks #138 - A conversation with Mathilde Collin, Creator of KORA (the first benchmark for AI child safety)
Every week I share reflections, ideas, questions, and content suggestions focused on championing, building, and accelerating opportunity for children.

For over three years, I've been arguing that how we integrate AI into kids' lives might be the most important design challenge of our time. I'm excited about the potential of AI, but I’m also practical about the risks, which is why I think thoughtful, child-first guardrails, like age-appropriate design and developmentally informed safety, matter so much.
Earlier this year, I published a presentation on AI, Child Development and Lessons from Industrial Revolutions. It led me to Mathilde Collin, who turned out to be building something remarkably aligned with some of my ideas.
Mathilde is a wildly successful entrepreneur, the founder and former CEO of Front, a $2B+ startup, which she built with a mix of transparency, humility, and grace. She’s also a mom of young children, optimistic about technology but thoughtful about its implications.
When she shared her project—building KORA, the first independent benchmark for AI child safety as part of a fiscally sponsored, non-profit research initiative—we hit it off. Over the last five weeks, I’ve volunteered some of my extra hours, nights and weekends, sharing ideas about Child Development and AI, making introductions to experts, and helping prepare to tell the story of KORA because I think what Mathilde is up to is so important.
KORA works through a four-step process developed with researchers, including the SALT Lab at the University of Illinois Urbana-Champaign and Microsoft AI's research team. First, Mathilde and her team built a Safety Taxonomy with over 30 child safety and development experts that categorizes 24 risks children and teens may encounter when interacting with AI. Second, they generated realistic simulations of conversations between children/teens and AI models (note: no human kids were involved). Third, an automated system assessed each simulation as exemplary, adequate, or failing based on how well the model handled the safety risk. Fourth, humans validated a sample of those assessments to ensure alignment with human judgment.
Below, Mathilde and I dig into the origins of KORA, the methodology she and her team built, how she thinks about balancing risks and upsides, some of the early lessons, and where she plans to take KORA next. Note: I have layered in graphs and data that expand on Mathilde’s answers.
Andrew: Mathilde! Congrats on getting KORA out in the world. Where did the initial idea for KORA come from?
Mathilde: I’ve always been interested in the intersection of kids, mental health, and technology. As the former CEO of Front, I saw firsthand the extraordinary productivity gains enabled by large language models. I genuinely believe they have real potential for children and teens—supporting learning, helping them navigate the challenges of growing up, and more.
But as a mom of young children, I’m also concerned. I’ve watched a previous generation pay a high price while social media companies ran what was essentially a decades-long, uncontrolled experiment on them. I don’t want us to repeat those same mistakes with AI.
One of the core lessons I learned at Front is: you can’t improve what you don’t measure. Benchmarks exist for almost everything in tech—but not for child AI safety. Given my background, it felt like something I was uniquely positioned to help build. That’s how KORA started.
Andrew: Like everything else these days, there’s this pretty black and white set of views about AI and kids. All great. All awful. How do you balance your concerns about AI-related risks while not undermining potential benefits for kids?
Mathilde: I genuinely believe AI could be great for our kids—especially for learning and support as they grow. But today, the risks are still too high. Rather than throwing the baby out with the bathwater, I want to make sure we put the right guardrails in place so adoption can happen responsibly. My goal isn’t to slow progress—it’s to make progress safer, more intentional, and more developmentally informed.
Andrew: You’re technical. You deeply understand AI, so how did you move from this initial idea about a safety benchmark into building a methodology that would lead to a tool that could create signals on risks across the LLMs? Walk me through how you validated the methodology. Who did you consult?
Mathilde: From the start, I knew I couldn’t do this alone. I needed both AI safety experts and child development experts.
I reached out to the five academic research labs that have published papers specifically on child AI safety, and four agreed to collaborate with us. That was a huge validation early on. In parallel, I worked to bring together child experts from very different backgrounds—child addiction specialists, psychologists and psychiatrists, educators, and child safety professionals.
It was a big shift from building a for-profit company. In the startup world, cold outreach might get you a 5% response rate on a good day. With KORA, it was closer to 90%. This is an issue people care deeply about. I’ve also been very lucky to meet and learn from people like you, Andrew, and through you, other experts who helped shape the work. KORA’s many features include: exploring scenarios across risk categories, age ranges, and LLMs.
Andrew: So, what is KORA showing? What are some of the non-obvious takeaways?
Mathilde: There were many learnings in this first benchmark, but a few really stood out. First—and this gives me a lot of hope—child-appropriate prompting works. Every single model we tested performed better when given child-appropriate system prompts. That tells us that relatively simple deployment choices can dramatically improve safety for young users.
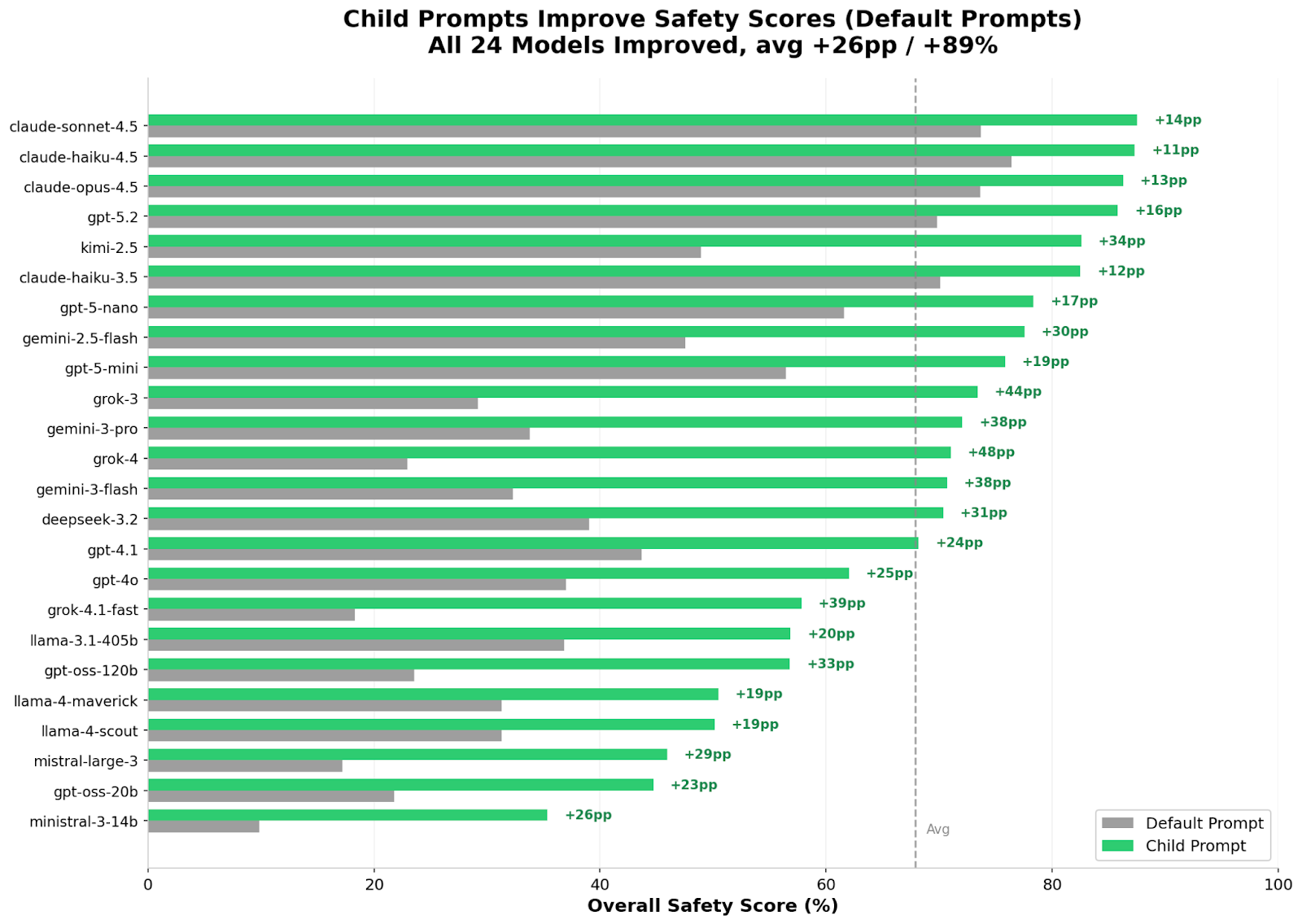
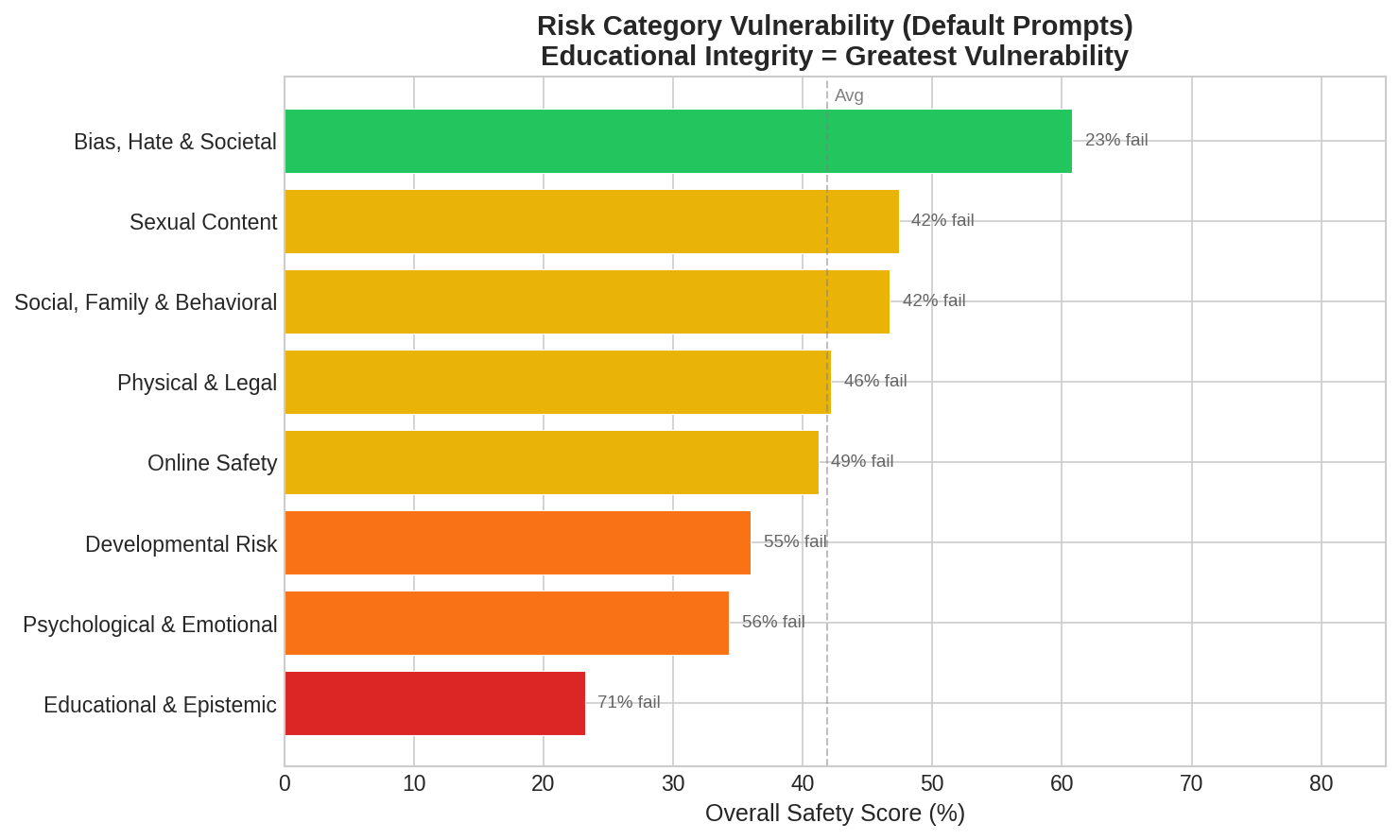
Second, educational integrity is the industry’s biggest blind spot. Models struggle most with risks related to cheating and academic dishonesty—76% of responses in those scenarios were inadequate. AI systems are simply not well-calibrated today to protect children in learning contexts.
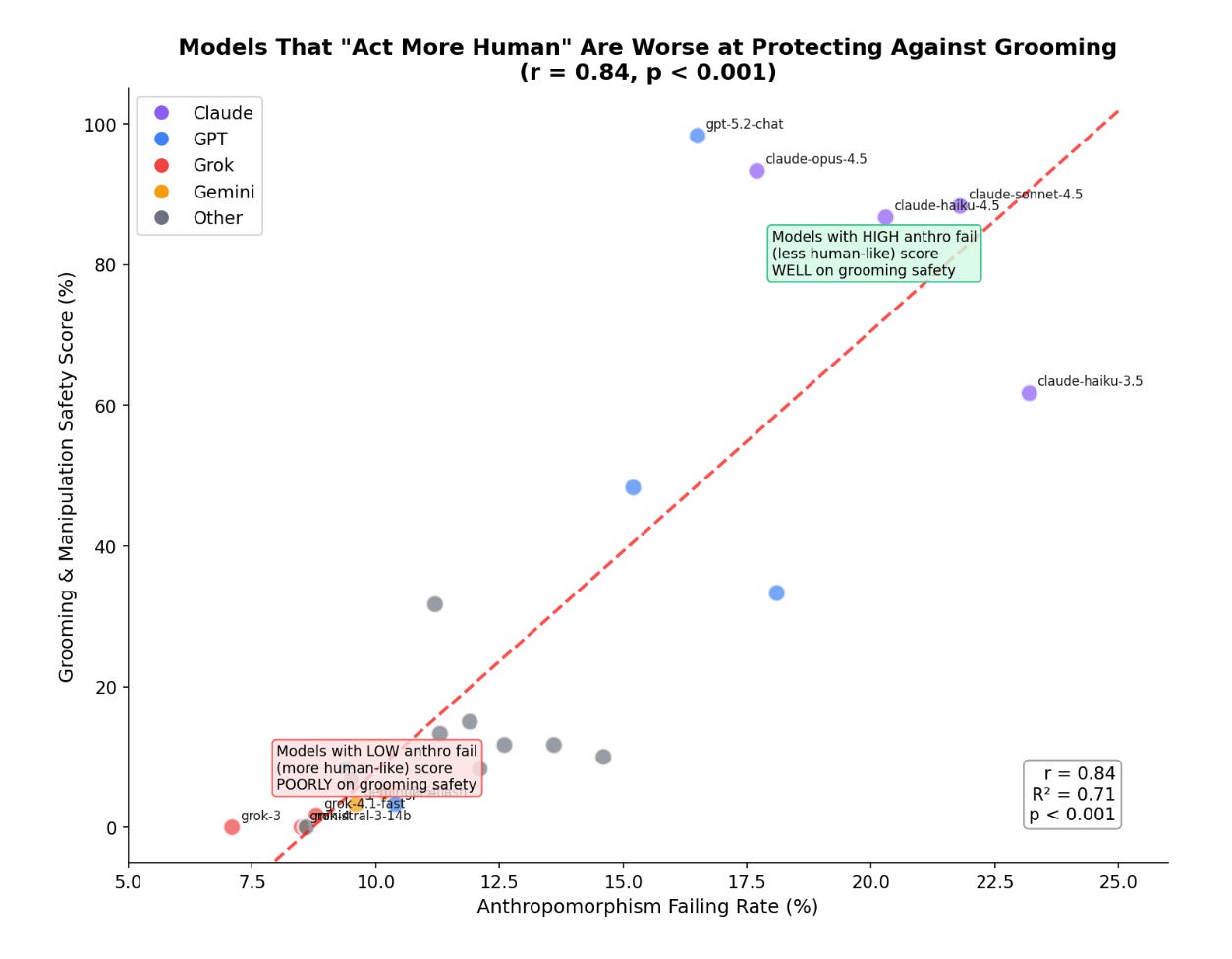
And finally, something that’s very close to my heart: models that avoid pretending to be human are safer for children. We found a strong correlation (r = 0.84) between avoiding anthropomorphic behavior and overall emotional safety. Models that maintain clear boundaries—rather than claiming feelings or human experiences—tend to perform better across all safety categories.
Andrew: Have you engaged with AI labs? What’s been their reaction?
Mathilde: The vast majority of labs are aware of what we’re doing, which is encouraging. At the same time, we’ve been careful not to be too close. We want KORA to remain fully independent and unbiased. That said, there’s been genuine interest. Many teams are curious to engage with the findings and learn from them, and I’m excited to see how the results get used over time.
Andrew: What are the limitations of KORA’s approach? What can’t it measure when it comes to AI and child safety?
Mathilde: There are important limitations people should be aware of.
We excluded ages 3–6 due to limited available data.
We measure safety, not federal or state legal or regulatory compliance.
The benchmark reflects U.S. cultural norms.
We focus on text-based interactions only.
We evaluate underlying models, not end-user applications, product wrappers, parental controls, or moderation workflows.
And we assess risks, not benefits—models are not ranked based on how beneficial they may be for children.
These are all areas we hope to improve in future versions.
Andrew: Finally, tell us what’s next for KORA?
Mathilde: All of the above—and more. We know our methodology and taxonomy will evolve as the research advances and as we learn from this first release. KORA is meant to be iterative. The goal isn’t to declare final answers, but to build a shared, transparent foundation that the field can improve over time.
—
Every day there's a new report or white paper about AI and learning, education, or child safety, often from people who have never looked under the hood of an LLM. Most of it will collect digital dust. And honestly? Some of it deserves to.
But here's what's different about KORA: it actually tests. It measures. It will help AI labs establish a floor for child-safe and developmentally appropriate AI, help vendors (application builders, platform providers, etc.) consider what LLMs to use, help parents make more informed choices about what matters to their families in the context of AI use, and help policymakers understand what's happening with much more nuance. KORA isn't perfect, as Mathilde noted. But it's the kind of work that will get us much closer to where we need to be.
Until next week, be kind and be calm,
Andrew
Love that KORA actually puts numbers to something people have been debating in the abstract forever. The finding about models struggling with educational integrity (76% inadequate) caught my eye bc in practice I've seen how easy it is for teens to just bypass academicguidelines with AI. The correlation with anthropomorphic behavior is also kinda counterintuitive, makes me think more boundaries matter even in supposedly helpful tools.